For the past two years, the dominant mental model for AI capability improvement has been scaling: bigger models, more training data, longer context windows. That model is not wrong, but it is increasingly incomplete. A growing body of research suggests that for complex, real-world tasks, architectural choices about how agents are composed and coordinated produce larger capability gains than raw model size alone.
The CoAct framework, published by researchers at Carnegie Mellon and collaborating institutions, provides some of the clearest empirical evidence for this claim. Their results — and the broader research context around hierarchical agent systems — have direct implications for how we should design and evaluate AI agent platforms.
What CoAct Demonstrates
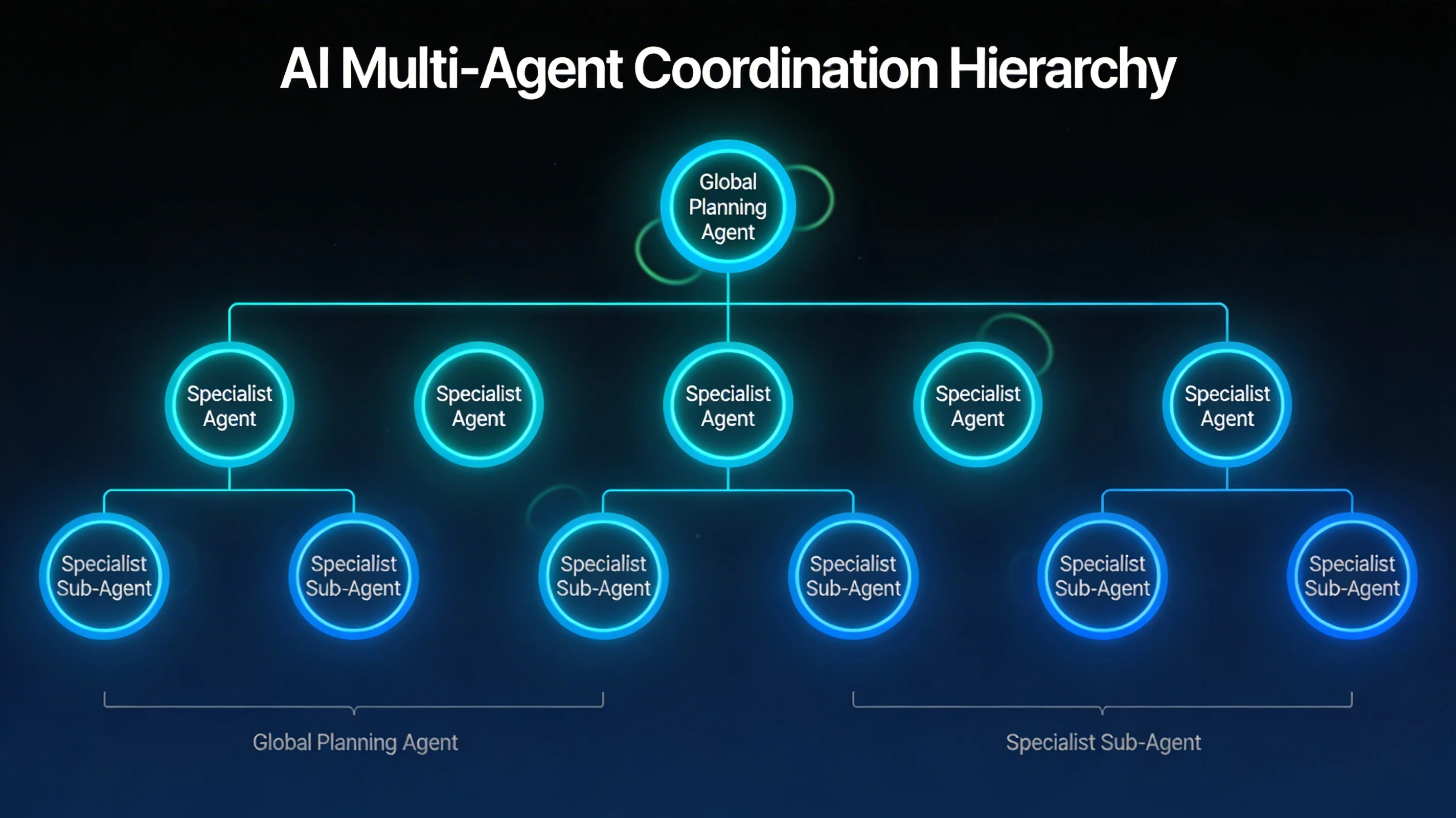
CoAct (Collaborative Action) addresses a fundamental limitation of single-agent systems: the inability to maintain coherent global context while simultaneously handling fine-grained execution details.
When a single LLM is asked to complete a complex task, it faces a context allocation problem. The more detailed the execution plan it maintains, the less working memory remains for tracking high-level goals, intermediate results, and error states. This creates a ceiling that is not purely about model size — it is about the structural mismatch between flat context windows and hierarchically structured tasks.
CoAct's solution is to separate agents by responsibility level:
- A global planning agent maintains the high-level task decomposition, tracks completed milestones, and makes replanning decisions when subtasks deviate from expectations
- Local execution agents receive scoped subtask descriptions and execute them with full attention focused on the immediate objective
- An arbitration layer manages information flow between levels, deciding what context needs to pass upward (errors, significant discoveries) versus what can be handled locally
On their benchmark suite — which includes multi-step software engineering tasks, research synthesis, and multi-system data workflows — CoAct outperformed the best single-agent approaches by 23% on task completion rate and showed significantly better performance on tasks requiring more than 15 distinct tool calls.
Why Decomposition Works
The intuition behind the performance gains is not complicated. When you decompose a task hierarchically, several things happen simultaneously:
Attention becomes focused. A local agent handling "fetch the API documentation for this endpoint and summarize the authentication requirements" can devote its full context to that specific objective. It does not need to track whether a database migration was completed four steps ago.
Errors become localized. When an execution agent fails, the failure is scoped. The global planner receives a failure report with context rather than a corrupted state across the entire task. Recovery means replanning one branch of the task tree, not restarting from scratch.
Parallelism becomes possible. Independent subtasks can be assigned to concurrent execution agents. A monolithic agent must execute everything sequentially because its state is shared and mutable. A hierarchical system can run non-dependent branches simultaneously.
Specialization becomes viable. Different subtasks benefit from different prompting strategies, tool sets, and even different base models. A global planner optimized for long-horizon reasoning and a code execution agent optimized for precise tool use are not the same system.
The Agent Registry Pattern
One practical implementation of hierarchical multi-agent architecture is the agent registry pattern: a central registry that maps task types to specialized agent implementations, with a dispatcher that routes incoming tasks to the appropriate agent based on task classification.
This is the pattern underlying Neumar's agent system. Rather than routing all tasks through a single general-purpose agent, the registry allows different agents — with different system prompts, tool sets, and execution strategies — to handle different task categories. A code generation task, a research synthesis task, and a project management task each benefit from different agent configurations.
The registry also enables capability composition. A task that begins as a code generation request might, partway through execution, require web research. Rather than forcing the code agent to handle research natively (degrading performance on both), the architecture supports delegation: the code agent can hand off the research subtask to a specialized research agent and resume once results are available.
LangGraph and Workflow-Based Coordination
For tasks that require explicit branching, parallel execution, and conditional routing, workflow-based coordination frameworks like LangGraph provide an important complement to the agent registry pattern.
LangGraph's state machine model is particularly well-suited to tasks where the execution path depends on intermediate results. Rather than pre-committing to a linear sequence of subtasks, a LangGraph workflow can define conditional edges — execute branch A if the research step returns a positive result, execute branch B otherwise — while maintaining checkpointed state that survives partial failures.
The combination of an agent registry (for mapping tasks to specialized agents) with a workflow engine (for coordinating multi-step, branching execution) covers the large majority of real-world complex tasks. The agent registry handles "what kind of agent should handle this?" and the workflow engine handles "in what order and under what conditions should the steps run?"
Neumar supports both patterns. Simple tasks route through the agent registry to single-agent execution. Complex, multi-phase workflows can be expressed as LangGraph graphs with parallel branches, MemorySaver checkpointing, and dynamic fan-out via the Send pattern.
When Monolithic Agents Still Win
Hierarchical architectures are not universally superior. For short, well-scoped tasks — a single code completion, a brief research question, a simple file transformation — the coordination overhead of a multi-agent system adds latency without adding capability.
| Factor | Monolithic Agent | Hierarchical Multi-Agent |
|---|---|---|
| Simple, well-scoped tasks | Faster, lower overhead | Unnecessary coordination cost |
| Complex, multi-phase tasks | Context ceiling, sequential only | Better decomposition and parallelism |
| Error recovery | Must restart entirely | Localized failure, branch-level recovery |
| Observability | Single conversation thread | Requires cross-agent tracing tooling |
| Specialization | One-size-fits-all prompting | Different models/prompts per subtask |
The crossover point depends on task complexity, but as a rough heuristic: if the task can be clearly specified in a single paragraph, a single agent is probably the right choice. If the task specification requires a numbered list of phases with decision points between them, hierarchical coordination is likely to outperform.
The other limitation is observability. A monolithic agent's reasoning is visible in a single conversation thread. A hierarchical system distributes reasoning across multiple agents, and tracing a failure requires inspecting the coordination layer as well as individual agent outputs. Good observability tooling — which captures both the plan structure and individual agent executions — is a prerequisite for operating hierarchical systems reliably.
Practical Implications for Agent Platform Design
The research on hierarchical architectures points to several design requirements for platforms that want to support production-grade agent workflows:
- A clean separation between planning and execution that allows the plan to be inspected, modified, and replanned independently of execution state
- An agent registry or similar mechanism that maps task types to specialized agent implementations
- Support for workflow-based coordination that can express branching, parallel, and conditional execution patterns
- Cross-agent observability that makes it possible to trace a complex task across multiple agent invocations
These are not theoretical features. As the task complexity frontier continues to advance — and the METR duration research suggests it will — teams that have built or adopted architectures with these properties will be able to handle increasingly complex tasks reliably. Teams working with monolithic single-agent pipelines will hit an architectural ceiling that cannot be resolved by simply upgrading to a more powerful model.
The empirical case for hierarchical multi-agent architectures is now strong enough that it should inform platform selection, not just system design conversations.