Agent workflow architecture is one of those topics where practitioners accumulate strong opinions quickly, often after building the wrong thing first. The choices made at the orchestration layer — how tasks are sequenced, how state flows between steps, how parallel work is managed — determine whether a workflow is maintainable, debuggable, and resilient to the partial failures that are inevitable in any system that talks to external services.
This guide covers the four major architectural patterns in production agentic systems today, with genuine guidance on which to reach for under what circumstances.
Linear Pipelines: Simple and Often Right
A linear pipeline executes steps in a fixed sequence, each step receiving the output of the previous step as its input. Despite — or because of — its simplicity, this pattern handles a surprisingly large fraction of real agentic workflows.
The canonical example: receive a Jira ticket, classify its priority, gather related context, generate a code fix, open a pull request. Each step depends on the previous step's output, no parallelism is required, and the overall workflow has a clear start and end. A linear pipeline maps directly to this shape with minimal overhead.
The engineering advantage of linear pipelines is diagnostic transparency. When something goes wrong, the failure is localized to a specific step with known inputs and outputs. There is no branching logic to trace, no parallel execution to reason about. The entire workflow state at any point is just the accumulated output of completed steps.
The limitation is equally clear: as soon as two steps are logically independent — as soon as you want to fetch data from two APIs simultaneously rather than sequentially — a linear pipeline forces artificial serialization that wastes wall-clock time. For human-scale tasks this rarely matters. For agent workflows operating over hundreds of items, it becomes a significant throughput constraint.
DAGs: Explicit Dependency Management
A Directed Acyclic Graph workflow encodes the dependency structure between steps explicitly. Steps execute as soon as their dependencies are satisfied, enabling natural parallelism without requiring the developer to manually coordinate concurrent execution.
DAGs are the right abstraction for workflows where the dependency graph is known at design time and does not change based on runtime data. Data ingestion pipelines are the canonical use case: transform A, B, and C in parallel; aggregate the results; run downstream processing. Airflow and similar tools have proven this model at scale over many years.
In agent contexts, DAGs work well when the agent's workflow structure is fixed but the content of each step is dynamic. An agent that always fetches three external data sources, synthesizes them, and generates a report has a fixed DAG shape regardless of what the sources contain. The workflow definition encodes the structure; the agent provides the reasoning within each node.
The DAG model strains when the workflow's structure depends on runtime decisions — when the number of steps, the branching factor, or the connectivity between steps is determined by data that only exists during execution. This is where state machines and the Send pattern become necessary.
State Machines: Explicit State and Conditional Transitions
A state machine workflow defines a set of explicit states and the conditions under which the workflow transitions between them. Unlike a DAG, where execution follows a fixed dependency graph, a state machine can cycle, branch conditionally, and route to different continuations based on the current state of the world.
For agent workflows, state machines are appropriate when the workflow needs to make genuine routing decisions — when the agent's action at state X depends on information that was not available when the workflow was designed. Approval workflows are a natural fit: a workflow that normally proceeds from "draft" to "submitted" but transitions to "revision-requested" if a reviewer rejects it cannot be expressed as a DAG without encoding the reviewer's decision as a structural choice at design time.
State machines also handle error recovery naturally. Rather than treating failure as a terminal condition, a state machine workflow can define explicit error states and recovery transitions: retry with backoff, escalate to human review, fall back to a simpler approach, terminate gracefully. This makes the error handling first-class rather than an exception-handling afterthought.
The cognitive cost of state machines is reasoning about reachable states and transition conditions, especially as the workflow grows. A state machine with ten states and conditional transitions between each pair requires care to ensure that the machine cannot reach invalid states or deadlock on missing transitions.
LangGraph and the Send Pattern
LangGraph 1.0 introduced a pattern for dynamic fan-out that addresses the core limitation of static DAGs: the Send pattern. A node can emit Send objects that dynamically spawn new node invocations, with each invocation receiving its own slice of state. This enables genuine data-driven parallelism where the branching factor is determined at runtime.
The archetypal example: an agent receives a list of search results and needs to scrape and summarize each one. The number of results is not known at workflow design time — it depends on what the search returned. The Send pattern handles this naturally:
function routeToScraping(state: ResearchState): Send[] {
return state.searchResults.map(
(result) => new Send('scrapeWebPage', { ...state, url: result.url })
);
}
Each Send spawns an independent invocation of the scrapeWebPage node, all running in parallel. When all invocations complete, their outputs are aggregated back into the main workflow state using reducer functions defined on the state annotation.
The reducer-based state aggregation is what makes the Send pattern composable. Each spawned node writes its result to the shared state, and the reducer determines how to merge multiple concurrent writes:
scrapedContents: Annotation<ScrapedContent[], ScrapedContent>({
reducer: (state, update) => [...state, update],
default: () => [],
}),
This pattern scales naturally from two parallel invocations to hundreds, with no structural changes to the workflow definition. The degree of parallelism is a runtime property determined by the data, not a design-time property fixed in the workflow graph.
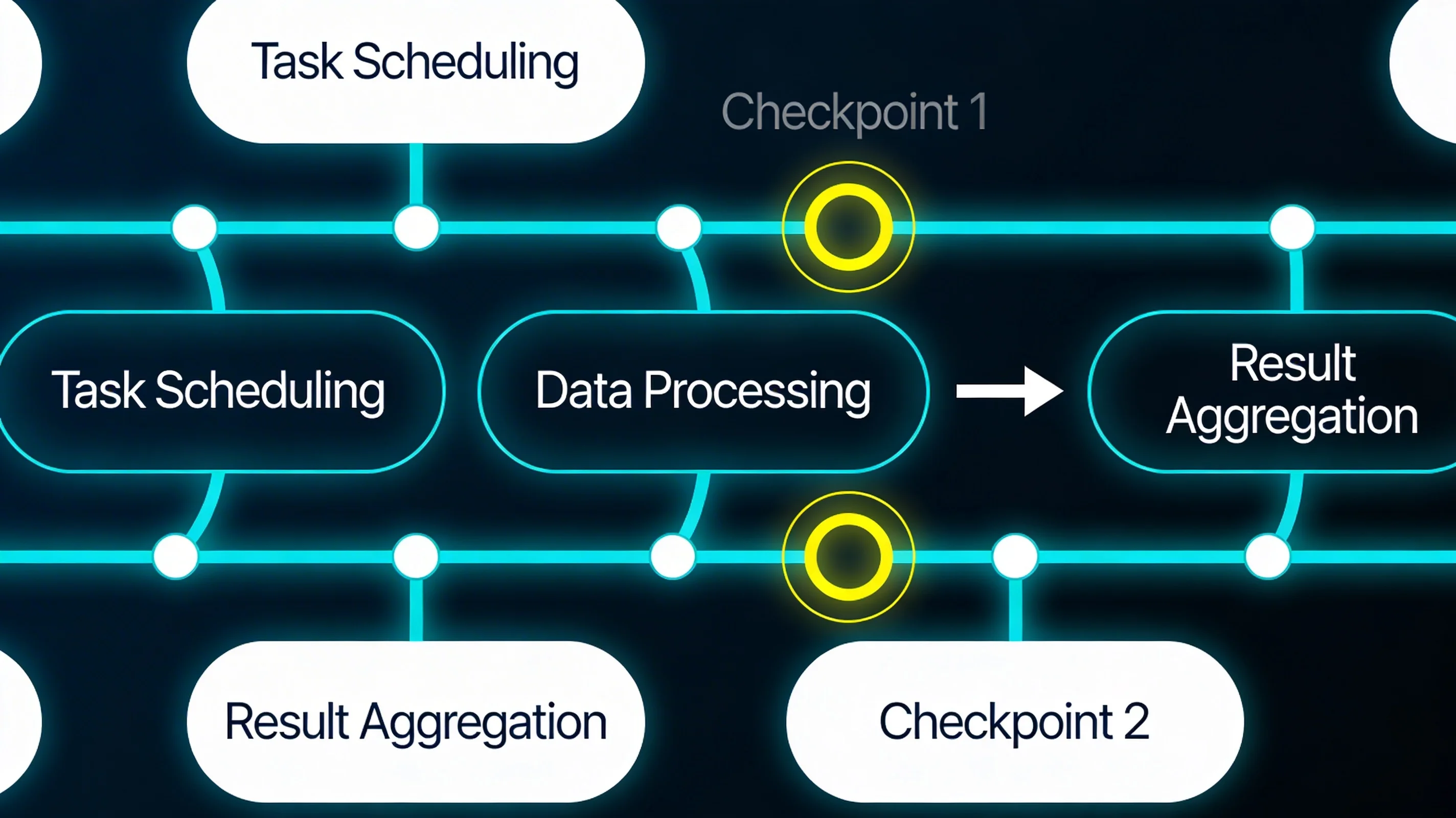
MemorySaver complements the Send pattern by providing built-in checkpointing. Long-running workflows that spawn many parallel nodes can be interrupted and resumed without losing progress. This is critical for agent workflows that might run for minutes or hours and encounter transient failures partway through.
Neumar's Approach: LangGraph Plus Structured Agents
Neumar supports both Claude Agent SDK-based structured agents and LangGraph 1.0 workflow agents, and the choice between them reflects the distinction between conversational task execution and complex workflow orchestration.
For tasks that fit a conversational model — iterative dialogue, tool use in response to user requests, dynamic planning over a single session — the Claude Agent SDK with two-phase plan-then-execute handles the majority of cases well. The planning phase externalizes the task decomposition as a reviewable artifact; the execution phase carries out the plan with adaptive re-planning when subtasks fail.
For workflows with explicit parallelism requirements — the Linear ticket-to-PR pipeline, multi-source research aggregation, batch processing over large item sets — LangGraph provides the orchestration primitives that the Agent SDK does not. The Send pattern enables the fan-out; MemorySaver provides the checkpoint resilience; the state annotation system makes the workflow's data flow explicit and type-safe.
The practical guidance: reach for LangGraph when your workflow has structural parallelism that would otherwise be serialized, when you need explicit checkpoint recovery, or when the workflow's branching structure depends on runtime data. Use the Agent SDK when the task is conversational and the planning structure emerges from the task rather than being encoded in the workflow definition.
Choosing the Right Architecture
The selection criteria come down to three questions:
| Pattern | Structure Known at Design Time | Supports Cycling/Recovery | Parallel Execution | Best For |
|---|---|---|---|---|
| Linear Pipeline | Yes (fixed sequence) | No | No | Simple sequential tasks |
| DAG | Yes (fixed dependency graph) | No | Yes (static) | Known parallel dependencies |
| State Machine | No (conditional transitions) | Yes | Limited | Approval workflows, error recovery |
| LangGraph Send | No (data-driven fan-out) | Yes (with MemorySaver) | Yes (dynamic) | Runtime-determined parallelism |
Is the workflow structure known at design time? If yes, a DAG or linear pipeline may be sufficient. If the structure depends on runtime data, you need Send-pattern dynamic dispatch or a state machine with conditional routing.
Does the workflow need to cycle or recover from partial failures? Linear pipelines and DAGs terminate; state machines and LangGraph with MemorySaver support recovery and resumption.
How important is parallel execution? For ten-item workloads, serialization overhead is negligible. For hundred-item or thousand-item workloads, the difference between sequential and parallel execution is the difference between a workflow that completes in seconds and one that takes hours.
Getting the architecture right matters more than getting the implementation right. A workflow built on the correct abstraction can be refactored; a workflow whose architecture fundamentally mismatches its requirements typically needs to be rebuilt. The time spent evaluating these tradeoffs before writing the first line of workflow code is consistently time well spent.